statsmodels 의 logit과 sklearn 의 logistic regression 은 분류 모델의 대표적인 python 라이브러리 입니다.
이 두가지 라이브러리의 간단한 예시와 차이를 포스팅 하고자 하는 글입니다.
우선 사용하는 Data는 kaggle의 titanic 을 사용할려고 하고 아래의 내용을 담고 있고, 성별을 의미하는행은 독립 변수가 명목형변수 이기때문에 이를 0,1로 수치형 변수로 변경되어 있습니다.

모델에서 사용 할 주요 컬럼별 의미
|
컬럴명
|
Survived
|
Pclass
|
Sex
|
Age
|
Sibsp
|
|
뜻
|
0 = dead
1 = Alive |
좌석별 등급
1 - first class 2 - second class 3 - others |
성별
0=여자 1=남자 |
나이
|
동행 인원수
|
Statsmodels logit
##라이브러리 불러오기
from statsmodels.api import Logit
##모델 학습
Logit_model = Logit(endog=train['Survived'], exog=train.drop('Survived',axis=1)).fit()
#종속변수 Y는 endog에 독립변수 x는 exog에 인자값으로 넣어준다.
##학습 모델 predict 적용하기
Logit_model_pred = Logit_model.predict(test.drop('Survived',axis=1))
#학습된 모델에 예측하고자 하는 데이터의 독립변수들을 넣어준다
print(Logit_model_pred.head())
1244 0.098985
798 0.084262
437 0.473411
84 0.572217
1307 0.086835
#각 항목에 1이 될 확률이 반환된다.
Logit_model_pred = Logit_model_pred.apply(lambda x : 1 if x >= 0.5 else 0)
#Threshold가 0.5 이상 일 때 1로 예측하기 위해 값을 변환 해준다.
test['PRED'] = Logit_model_pred
test.head()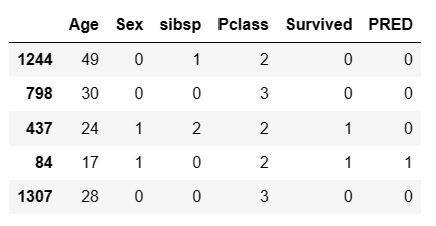
Statsmodels 의 Logit 함수는 이름에서도 알수있듣이 logit을 활용 하여 독립변수들 각각의 승산을 구하여 종속값 y를 예측하는 모델로써 predict를 적용한 결과 값에는 종속변수 y가 1을 취할 확률을 가지게 된다.
종속변수가 명목형 변수일때는 종속변수명의 값을 0과 1로 변경 해주어야 되고,
결과값은 1일 확률이 나타난다.
코딩에서 0은 False를 1은 True를 가지기 때문에 이와 같이 나타내는 것 같다
이후 독립변수의 회귀 계수 및 절편을 알고 싶으면 OLS와 동일하게 params 혹은 summary를 통해 알 수 있다.

sklearn.linear_model.LogisticRegression
##라이브러리 불러오기
import pandas as pd
from sklearn.linear_model import LogisticRegression
#Logistic 학습시키기
Logistic_model = LogisticRegression().fit(X=train[['Pclass','Sex','Age','sibsp']],y=train["Survived"])
#학습모델로 결과 예측
Logistic_pred = Logistic_model.predict(test[['Pclass','Sex','Age','sibsp']])
#결과 확인
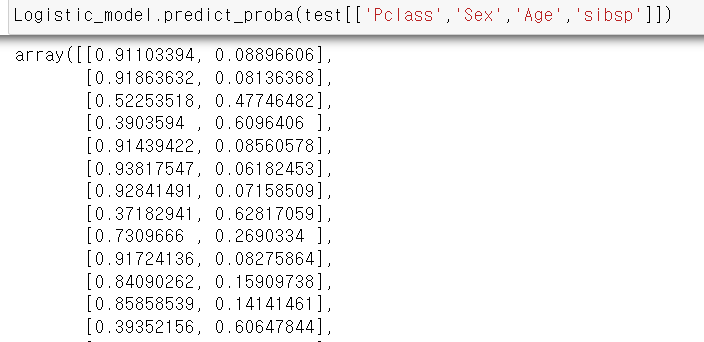
Logistic_model.predict_proba(test[['Pclass','Sex','Age','sibsp']])
pred = Logistic_model.predict(test[['Pclass','Sex','Age','sibsp']])sklearn 의 LogisticRegression 또한 statsmodels 의 logit과 동일하게 학습 및 결과 예측 하는 부분은 같으나
sklearn의 predict를 적용하면 임계값을 기준으로 결과만 반환 하게 해준다.
각 변수별 종속변수의 승산을 알고 싶다면, predict_proba를 활용하여 확인 할 수 있다.
순서는 0, 1의 순서이고 List안에 [ 종속변수가 0일 승산, 종속변수가 1일 승산] 이 적혀있다.
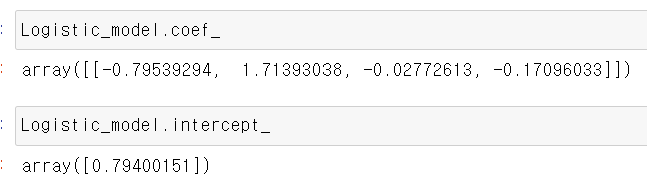
Statsmodels logit vs sklearn.linear_model.LogisticRegression
눈치 빠른 사람은 알겠지만 위의 회귀 계수 결과만 보더라도 각 모델은 인자값을 default로 두게 된다면,
결과 및 회귀 계수가 다를 수도 있다.
sklearn의 경우 fit_intercept 를 통하여 절편 유무를 설정이 가능하고,
머신의 학습 최대 반복 횟수 성절 기능, 이중 분류 이외의 다중 분류 옵션,
다중 분류 방법에 따른 다양한 솔루션 선택이 가능하고,
solver == 'sag', 'saga', 'liblinear' 에 따른 데이터 셔플을 위한 random_state를 선택 할 수있다.
즉 sklearn이 Logit 보다 좀더 다양한 옵션으로 사용이 가능하고 이러한 옵션들은 아래와 같이 사용 할 수 있다.

실제로 이전의 default로 학습한 모델과 계수가 다른것을 알 수있다.
독립변수에 대한 승산비 구하기
로지스틱 회귀계수에서 명심 해야되는 부분이 있다.
로지스틱 회귀계수는 각 독립변수의 odds를 설명하는 설명 변수이고,
값 증가에 따른 종속변수에 미치는 승산비를 구하고자 한다면 logit을 구해야 된다.
이는 numpy 의 exp 함수로 구할수있다.
exp()안에 실수를 넣어준다면 e의 지수에 값을 넣은 값이 리턴된다.
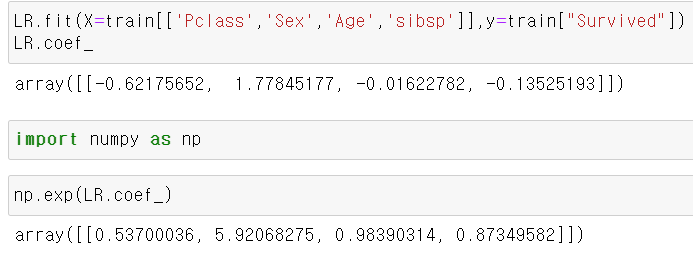
np.exp 안의 각각의 값이 각 독립변수에 대한 승산비이다.